

Over the past few decades, the subject area of data warehousing has seen a fair share of changes. Among the most popular approaches is Kimball’s dimensional modelling methodology, which has long been the gold standard for the last 30 years for its simplicity and business-friendly design. But in today’s modern data stacks and landscapes of big data and real-time analytics, one question keeps cropping up at conferences and discussions alike: Is Kimball data modelling dead?

For those who might be new to the conversation, Ralph Kimball introduced a methodology that centers on the creation of star schemas. These are simplified structures designed to improve query performance (denormalizing datasets to smaller dimensional subsets of data) and ease of understanding of complex data models. The idea is straightforward, organize data into facts (measurable events) and dimensions (contextual details), thereby providing a clear pathway for decision-makers to extract insights without wading through overly complex data structures.
In the good old days (well, maybe just a few years ago), things were a lot simpler. You would use ETL tools like SAP Data Services or Informatica to extract data, convert it into useful dimensions and measures, and then load i into your warehouse. These tools made it straightforward to manage relationships between tables, keeping primary keys and foreign keys well-organized.
In a Kimball-style warehouse, this kind of structure was great. The clear definition of data relationships made analytics and reporting much more efficient, allowing business users to easily manipulate the data while OLAP cubes functioned seamlessly.
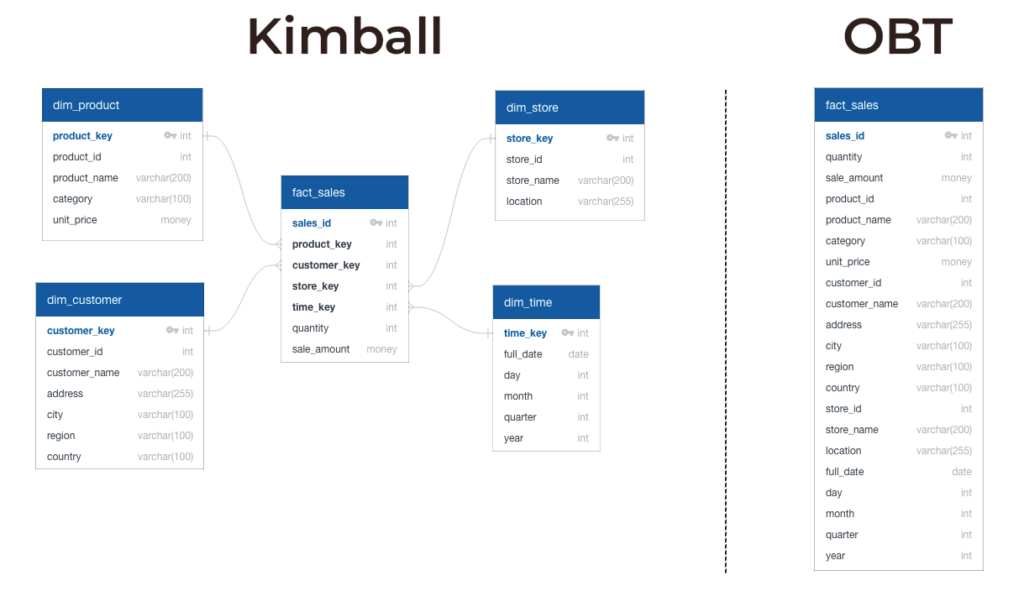
Fast forward 30 years, modern data architecture looks alot different from when Kimball first introduced his methodology. Cloud storage is cheap, computing power is abundant, and we’re dealing with diverse data types that Kimball never considered in these types of models. Tools like Snowflake and Databricks handle massive amounts of raw data efficiently by storing data in columnar storage and throwing compute power to our queries. This leads us to ask: Do we really need careful dimensional modeling when we can simply merge all the data into one big table (OBT)?
What is OBT?
Modern cloud platforms like Snowflake and Databricks have made it easier than ever to store and process huge amounts of raw data. With OBT, instead of breaking data into multiple tables, you merge everything into one large table, essentially limiting amount of tables and merging the final product of a data model to a materialized table instead.
The One Big Table approach offers a lot of agility and flexibility. It’s quick to set up and easily adapts to varied data sources, which means you can start gathering insights with minimal upfront work. This streamlined process often results in lower initial overhead, allowing you to bypass many data transformations early on. Additionally, modern cloud platforms handle massive single-table datasets with ease, making scalability a strong advantage.
This approach isn’t without its problems either. Without the clear boundaries provided by a dimensional model, there’s a higher risk of data redundancy, which can clutter your dataset over time, and trust me – your users will quickly notice. It also lacks reusability, if you for instance would like to use certain parts of your model in a new smaller initiative. This will over time lead to data duplication and can will easily become a source for creeping technical debt. While modern computing power helps, querying a huge, flat table may not always perform as efficiently as a well-organized schema. As the table grows and becomes more complex, maintaining clarity can become increasingly challenging, where you for example keep different levels of aggregations in one table.
Rather than viewing Kimball and OBT as competitors, I like to think of them as tools in your data architect’s toolbox, each suited to different scenarios. For organizations with a clear need for robust, business focused reporting and historical analysis, Kimball’s dimensional modeling provides clarity and performance that’s hard to beat. Meanwhile, for teams operating in fast-paced, data-diverse environments where exploratory analysis and real-time insights are key, OBT offers the flexibility and speed needed.
By understanding where each approach fits in and where it might fall short, you can design hybrid solutions that utilizes the strengths of both methodologies. For instance, you might use an OBT setup to capture and explore raw data, and then apply Kimball’s structure to create polished, business ready data when the data and requirements have stabilized. This has approach has increased in popularity, specifically through the medallion architecture.
My Thoughts
My take, is that declaring Kimball data modeling is dying might be a bit premature, I would instead say that it’s evolving. It depends on your landscape, architecture and what you want to achieve. Also, there are many more approaches that just Kimball or OBT – like data vault modelling, 3NF and more. This field is is so massive and flexibile, that there are no “right or wrong” way to do this, its all about context.
For companies with a clear need for robust, business focused reporting, the tried-and-true methods of Kimball still offer best in class benefits. On the other hand, in environments that demand high levels of flexibility and scalability, where context and reusability of assets is not necessarily that important, OBT might be a good way to go.
Rather than viewing Kimball data modelling as a relic of a bygone era, it might be more realistic to see it as one of many tools in the modern data architect’s toolbox. In my opinion, it is still as relevant today as it was 30 years ago. By understanding where Kimball excels and where an OBT approach might offer more flexibility, you can design hybrid solutions that captures the best of both worlds.
So, what’s your take? Are you keeping the Kimball approach alive for its proven benefits in your modern environment, or have you already started exploring more agile OBT strategies? Would love to hear your thoughts.
